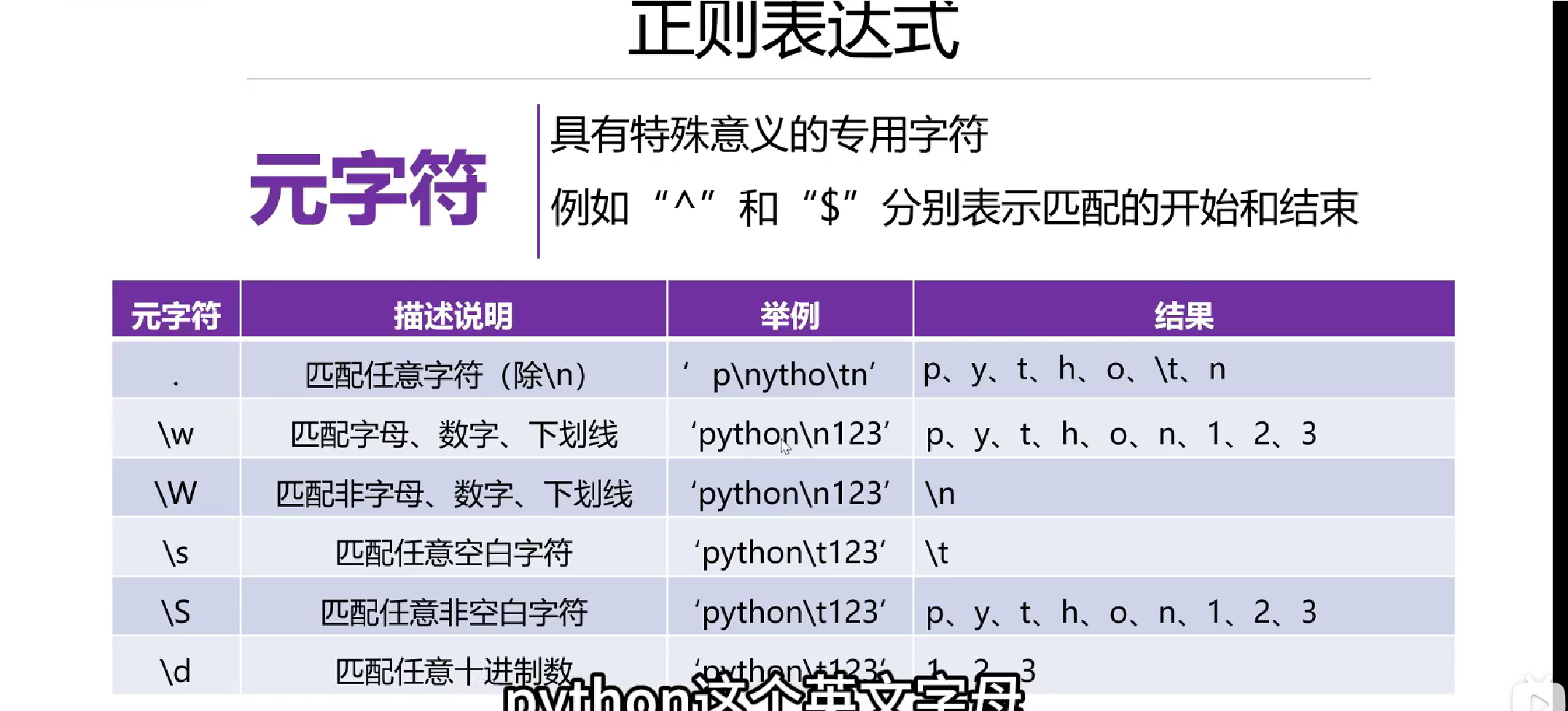
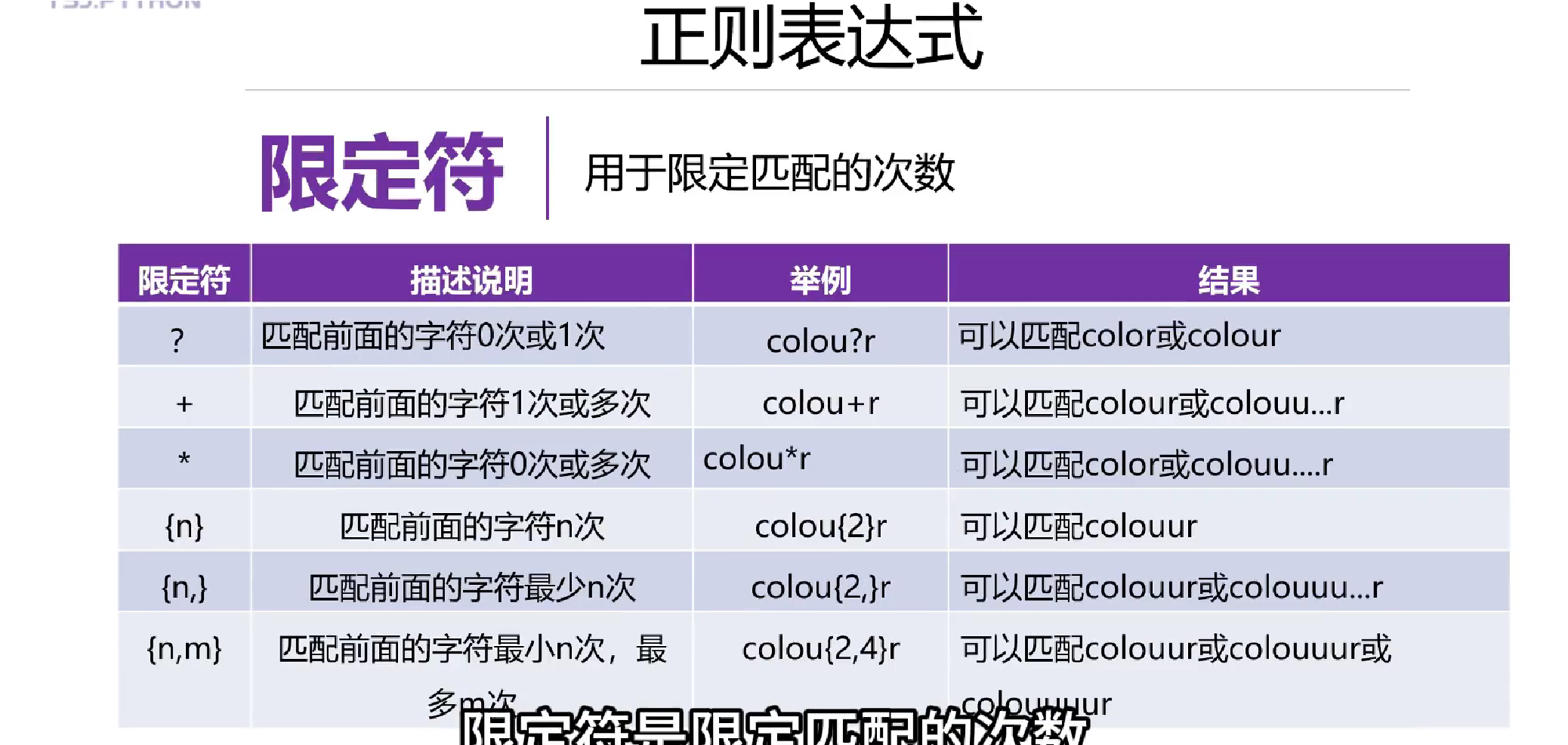
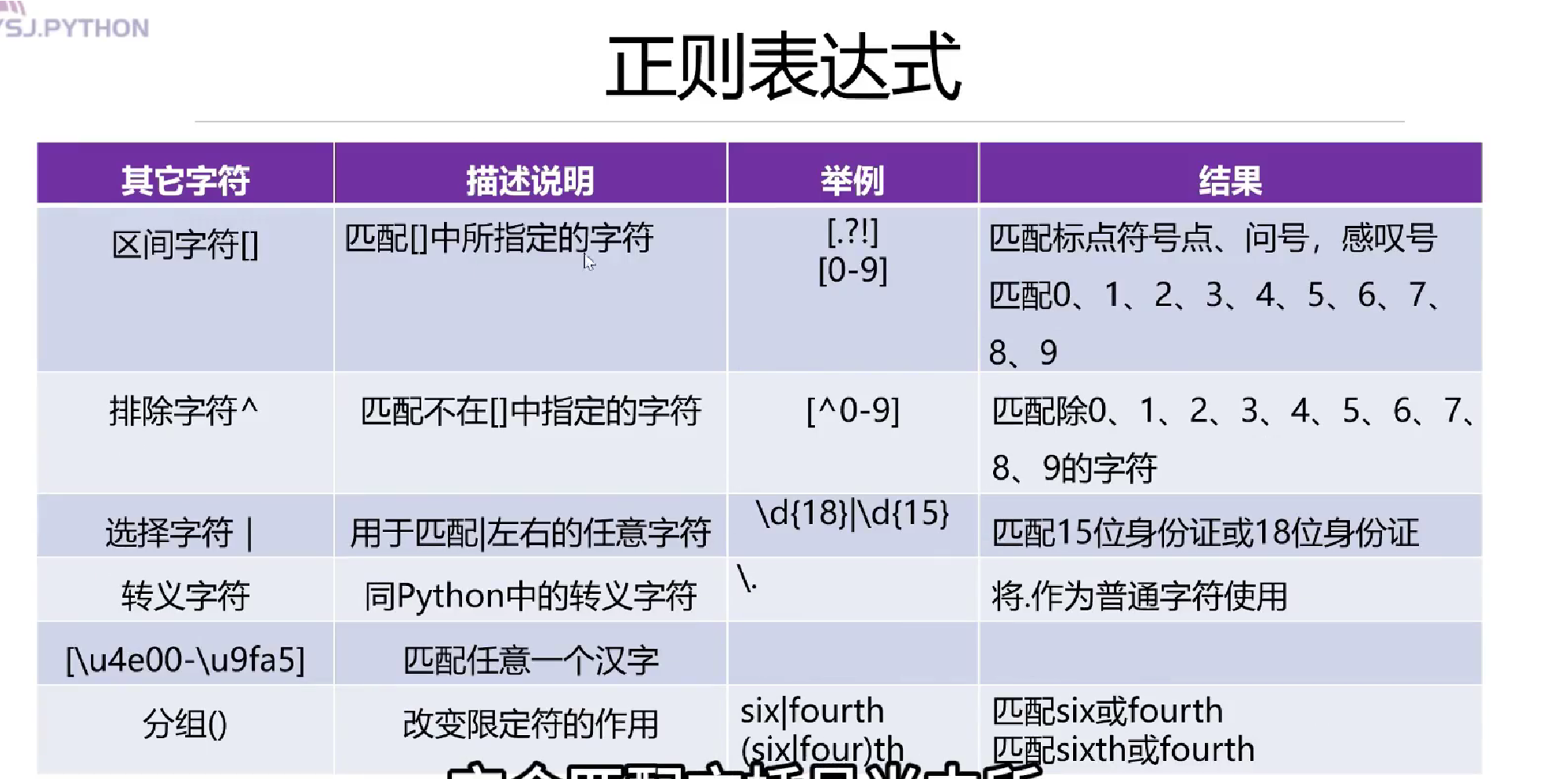
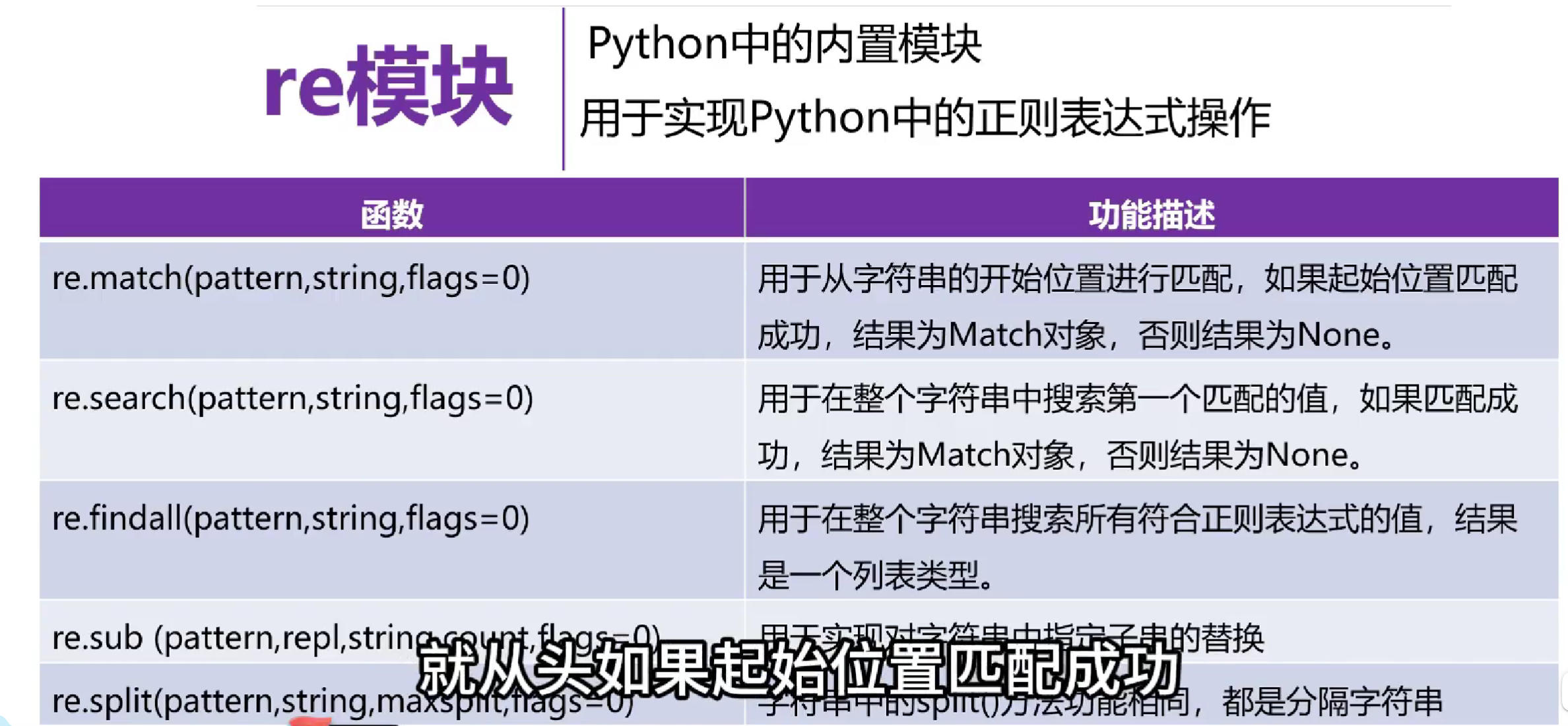
基础知识:
简要示例:
import re # 模块导入
pattern = '\d\.\d+'
s = 'I study python 3.11 everyday'
s2 = '3.7 I study python 3.11'
# match的使用,返回是match对象
match = re.match(pattern, s, re.I)
match2 = re.search(pattern, s, re.I)
# match是从头开始匹配,如果不符合直接返回None
#
print(type(match2))
print(match) # <re.Match object; span=(15, 19), match='3.11'>
# search的使用,多个匹配只匹配第一个
print('匹配值的起始位置:', match2.start())
print('匹配值的结束位置:', match2.end())
print('匹配区间的位置元素:', match2.span())
print('待匹配字符串:', match2.string)
print('匹配的数据:', match2.group())
print('----------------')
print(match) # None
# findall使用,返回是列表
lst = re.findall(pattern, s2)
print()
print(lst)
# sub使用,返回类型是str
pat = '爬虫|黑客'
s3 = '我想学习爬虫,当一名黑客可以吗'
lst = re.sub(pat, 'XXX', s3)
print(lst, type(lst))
# \S 匹配非空字符
print('----------------------')
pat2 = "\S"
s4 = "python\t 123"
print(re.findall(pat2,s4))